Gemini TTS voices are now available, a long-requested feature.

Gemini TTS is an LLM-based text to speech service like OpenAI. It can understands context, emotions. There an optional prompt parameter which lets you customize the speaking style, where you could put for example pronounce in an angry voice, or use a british accent. The language_code is optional, it's more of a hint but not required, even if you generate audio for non-English text.

There are a few models available. You may not see a ton of difference between them:
gemini-3.1-flash-tts-preview: latest model, which I would recommend for most people. Supports emotion / sound effect tagsgemini-2.5-flash-tts: quick to generate audiogemini-2.5-pro-tts: provides a high degree of control over speechgemini-2.5-flash-lite-preview-tts: low latency, for interactive use. This may not be as interesting for Anki usersThe tags that you can insert in the text are reminiscent of ElevenLabs v3, for example the [laugh] tag in the example below. For full details on how to use them in conjuction with the prompt, look at the Gemini TTS prompting guide.

There are other differences in HyperTTS, the error-handling has been improved. When generating batch audio, HyperTTS will automatically retry in case of timeouts or other transient issues. This was a pre-requisite for Gemini, because up until recently the generate quota from Google was very low, something like 10 requests per minute. Without the automatic retry functionality, it would quickly turn into a very frustrating exercise to generate large amounts of audio. Currently the retry logic is automatic and HyperTTS will retry up to three times.
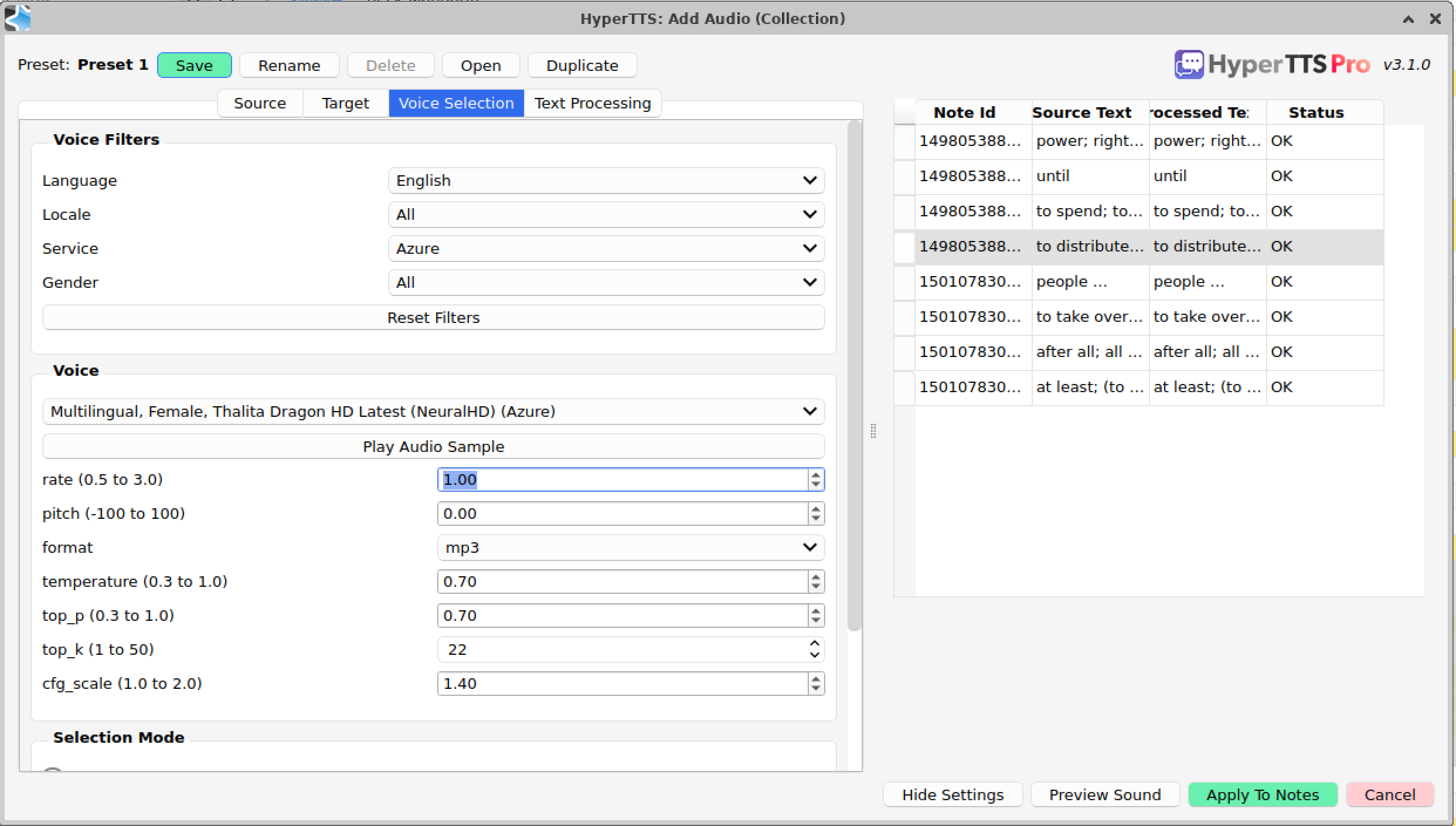
Azure DragonHD voices are a new addition and also promise very high quality. The blog post here explain how to set the parameters however in my experience the changes are very subtle.
On ElevenLabs, you can now set the voice speed along with other parameters that were missing previously.