Gemini TTS voices are now available, a long-requested feature.

Gemini TTS is an LLM-based text to speech service like OpenAI. It can understands context, emotions. There an optional prompt parameter which lets you customize the speaking style, where you could put for example pronounce in an angry voice, or use a british accent. The language_code is optional, it's more of a hint but not required, even if you generate audio for non-English text.

There are a few models available. You may not see a ton of difference between them:
gemini-3.1-flash-tts-preview: latest model, which I would recommend for most people. Supports emotion / sound effect tagsgemini-2.5-flash-tts: quick to generate audiogemini-2.5-pro-tts: provides a high degree of control over speechgemini-2.5-flash-lite-preview-tts: low latency, for interactive use. This may not be as interesting for Anki usersThe tags that you can insert in the text are reminiscent of ElevenLabs v3, for example the [laugh] tag in the example below. For full details on how to use them in conjuction with the prompt, look at the Gemini TTS prompting guide.

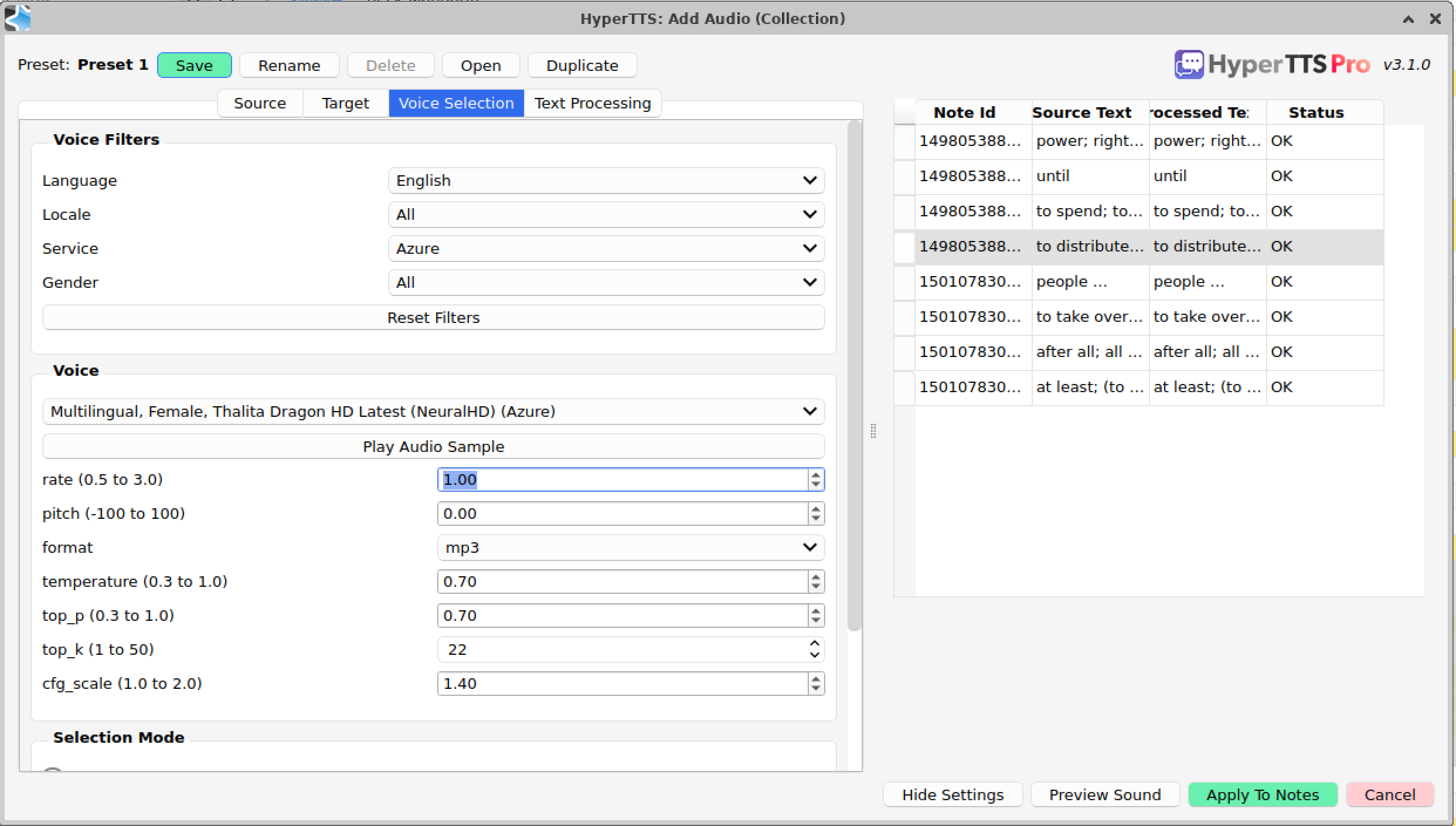
There are other differences in HyperTTS, the error-handling has been improved. When generating batch audio, HyperTTS will automatically retry in case of timeouts or other transient issues. This was a pre-requisite for Gemini, because up until recently the generate quota from Google was very low, something like 10 requests per minute. Without the automatic retry functionality, it would quickly turn into a very frustrating exercise to generate large amounts of audio. Currently the retry logic is automatic and HyperTTS will retry up to three times.
Azure DragonHD voices are a new addition and also promise very high quality. The blog post here explain how to set the parameters however in my experience the changes are very subtle.
On ElevenLabs, you can now set the voice speed along with other parameters that were missing previously.
ElevenLabs v3 is now available in HyperTTS 2.10. This is a new model from ElevenLabs which allows controlling the emotion of the generated speech using special keywords: https://elevenlabs.io/v3.
There is also a change with the FPT.AI Vietnamese TTS service (see below).

To use the new model, you have to pick one of the v3 (alpha) voices in the ElevenLabs service. Different models appear as a variant of the same voice.
.png)
The difference between models is explained here: https://elevenlabs.io/docs/models test. Some models like Flash 2.5 and Turbo 2.5 are optimized for latency (they will generate faster). If you are batch-generating, this generally won't be a concern for you and you will instead want to pick the higher quality models such as Multilingual v2 and Eleven v3. The new v3 model has two significant improvements.
From the ElevenLabs v3 model page:
The Eleven v3 model supports 70+ languages, including:
Afrikaans (afr), Arabic (ara), Armenian (hye), Assamese (asm), Azerbaijani (aze), Belarusian (bel), Bengali (ben), Bosnian (bos), Bulgarian (bul), Catalan (cat), Cebuano (ceb), Chichewa (nya), Croatian (hrv), Czech (ces), Danish (dan), Dutch (nld), English (eng), Estonian (est), Filipino (fil), Finnish (fin), French (fra), Galician (glg), Georgian (kat), German (deu), Greek (ell), Gujarati (guj), Hausa (hau), Hebrew (heb), Hindi (hin), Hungarian (hun), Icelandic (isl), Indonesian (ind), Irish (gle), Italian (ita), Japanese (jpn), Javanese (jav), Kannada (kan), Kazakh (kaz), Kirghiz (kir), Korean (kor), Latvian (lav), Lingala (lin), Lithuanian (lit), Luxembourgish (ltz), Macedonian (mkd), Malay (msa), Malayalam (mal), Mandarin Chinese (cmn), Marathi (mar), Nepali (nep), Norwegian (nor), Pashto (pus), Persian (fas), Polish (pol), Portuguese (por), Punjabi (pan), Romanian (ron), Russian (rus), Serbian (srp), Sindhi (snd), Slovak (slk), Slovenian (slv), Somali (som), Spanish (spa), Swahili (swa), Swedish (swe), Tamil (tam), Telugu (tel), Thai (tha), Turkish (tur), Ukrainian (ukr), Urdu (urd), Vietnamese (vie), Welsh (cym).
Previously the Multilingual v2 model only supported 29 languages.
Believe it or not, this new v3 model can not only generate voice, but also sound effects ! See here Eleven Labs v3 Prompting guide for full details. Obviously this kind of customization of the audio is not an absolute must for language learning flashcards, but if you spend a lot of time reviewing, it's nice to have a bit of fun with your cards.
[giggles], [laughing], you could add a laugh in the middle of the dialogue.[happy], [excited] will change the emotion in the voice[applause], [clap] also work... for pausesCAPITALS for emphasis.

This is not related to the new Eleven Labs v3 model, and in fact only works with the Eleven Flash 2.5 and Eleven Turbo 2.5 models. It allows you to instruct to the model that your source text is in a particular language, like fr for French. You have to use an ISO 639 language code. This change was contributed by user Wylan on github:
Dutch has a fair number of words that are spelled the same as German or French words (often because they originated in those languages). They are unfortunately pronounced differently though, especially when they contain the letter "g". Using the multilingual models and whatever they do to guess the target language it usually seems to guess German or French. Which to be fair are both much more commonly used language so it does make sense. It does however make it pretty hard to get the correct pronunciation when you're studying Dutch!
There has been a change to the FPT.AI service. Previously, HyperTTS Pro users had to the FPT.AI service. This service unfortunately stopped working for me and I couldn't login, and couldn't add more credits. Their customer support was unresponsive. I realized they also were now offering those same TTS voices on their newer cloud marketplace. So HyperTTS Pro users now have access to this new service, which seems more convenient for international users, and supports international payment options. For those who still want to use the existing FPT.Ai service, you can use the FptAiClassic service in HyperTTS with your own API key. (You will most likely need a Vietnamese payment option such as VNPay) to use it.
Introduce YouDao service based on the Dictionary website YouDao. Fixed bugs with Duden service (another dictionary based service). Other small fixes.
The OpenAI gpt-4o-mini-tts model is now supported in HyperTTS. This is a feature contributed by Claus (thank you!). You have to select it in the voice options (the default is still tts-1-hd for OpenAI). This voice model accepts an optional instruction field. You can use it to instruct the model to speak in a certain way, or indicate that the source text is in a particular language. For more details, you can consult the OpenAi reference. As with neural and LLM models, the actual output will really vary with the situation, so you'll have to experiment. Claus' feedback is: GPT-4o mini TTS is the first OpenAI TTS model that provides usable output for my Greek flashcards. The common feedback with OpenAI (and also ElevenLabs) is that non-english output was not that good and suffered from an american accent. Hopefully this new model improves that.

So what's next ? People have been asking for Google Gemini TTS. I've been working on this for HyperTTS but there's a serious limitation, google limits requests to 10 per minute, even on Tier 1 paid accounts. This means mass-generating Gemini audio will be a tedious process, and HyperTTS will need to implement some retry logic, which will be welcome anyway, to handle the occasional timeout. Besides that here are the issues that I will tackle in the coming weeks in HyperTTS.
Aside from that, in the coming months, I'd like to make progress on an idea I started before Christmas: generating long-play audio files with Anki flashcard sounds, so that you can review your deck while walking. Kind of like a podcast. I have a working prototype but I need to finish it. I'm also actively thinking about how Language Tools can use LLMs. This is honestly an overdue feature given how AI chatbots have become amazing at translation, but also transliteration (for Chinese, you can confidently ask gpt-4 to convert to Pinyin).
HyperTTS 2.3.0 is out with an updated voice list. It now supports Google Chirp voices which are supposed to compete in quality with ElevenLabs voices.
Alibaba Cloud is now supported. This is a community contribution from zzzerk. Alibaba can be interesting if you're looking for more diversity in Mandarin voices (for example they have child voices). Overall I still think Azure voices are better, but it's always good to have more choice.

Also, keyboard shortcuts are now supported in Easy mode. You have to configure those shortcuts in the HyperTTS Preferences screen:



HyperTTS has a new Easy mode which provides a simplified interface for adding audio one note at a time, either during editing or note creation. A lot of users favor this mode, which is closer to how AwesomeTTS functions. In this mode, audio addition is not automated, you have to do at least two clicks to add a note, but it gives you an opportunity to customize the input text before generating the audio, which is important for Japanese and other languages where the default TTS output may not be perfect. Once you add audio, it will remember the settings and will present the same settings next time for the same Note Type and Deck combination.
When you bring up the Add Audio (Easy) dialog, it will try to get input text from three places:
You can switch between these sources using the radio buttons at the top of the dialog.

As a reminder, the Speaker, Play and Gear icons in the Anki editor toolbar are used to add audio while editing or adding a note. These buttons can also be activated with a keyboard shortcut. With the addition of Easy Mode, the meaning of those buttons change:
Speaker Button: brings up the Add Audio (Easy) dialog. You can then listen to a preview and add the audio if you are satisfied.Play Button: also brings up the Add Audio (Easy) dialog, exactly like the Speaker Button. There is no difference between the two buttons in easy mode.Gear Button: shows you the default preset for the current Note Type and Deck (Preset Rules Dialog). From that screen, you can access the more advanced settings. Speaker Button: will apply audio according to your preset rules with a single click.Play Button: will play the audio according to your preset rules, to confirm that the audio output is correct.Gear Button: allows you to configure your preset rules for the current Note Type / Deck combination.Advanced mode is more complicated, it requires you to setup a preset upfront. But once you've done so, you can add audio with a single click, or with a keyboard shortcut (configurable in Preferences)

The first time you click either the Speaker or Play buttons, you will be given a choice between Easy and Advanced mode. HyperTTS will remember this setting, but you can change it at a later time by going to the Preset Rules dialog as shown below:

Separately, in this new version 2.0.1, HyperTTS uses anonymous usage stats and error reporting. This helps us fix issues very quickly to provide the best experience for everyone. You can disable this functionality in the Preferences dialog (Anki main screen, Tools menu, HyperTTS: Preferences).

HyperTTS will now display the status all preset rules when previewing or generating audio. Errors no longer prevent generation of audio for other rules. You can now scroll in the preset rules window. These changes should make life easier for those who have a lot of preset rules.
HyperTTS 1.12 is out, with better Multilingual voice support.

More and more TTS services offer multilingual voices these days and this led to a confusing situation in HyperTTS where the same voice appeared under multiple languages. Starting with this version, multilingual voices only appear once, but they can be filtered in the Voice Selection screen according to the languages they support.
Azure Standard voices have been deprecated, and you will have to re-create presets which used those. The standard voices were removed from Azure around six months ago.
A MacOS service has been introduced, which lets you use free MacOSX voices if you are a mac user.
Finally, there's a scrollbar in the voice list, and the dropdown is bigger, to allow you to see more voices.